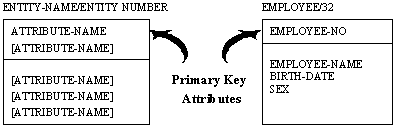
Figure 4-8 Attribute and Primary Key Example
An entity must have an attribute or combination of attributes whose values uniquely identify every instance of the entity. These attributes form the "primary-key" of the entity. For example, the attribute EMPLOYEE-NUMBER might serve as the primary key for the entity EMPLOYEE, while the attributes EMPLOYEE-NAME and BIRTH-DATE would be other attributes.
Within an IDEF1X model, every attribute is owned by only one entity and every instance of the entity must have a value for every attribute associated with the entity. That is, the attribute must be applicable to every member of the set of things represented by the entity. The attribute MONTHLY-SALARY, for example, would apply to some instances of the entity EMPLOYEE but probably not all. Therefore, a separate but related entity called SALARIED-EMPLOYEE might be identified in order to establish ownersh ip for the attribute MONTHLY-SALARY. Since an actual employee who was salaried would represent an instance of both the EMPLOYEE and SALARIED-EMPLOYEE entities, attributes common to all employees, such as EMPLOYEE-NAME and BIRTH-DATE, need not be an attribute of the SALARIED-EMPLOYEE entity.
In addition to attributes "owned" by the entity, that is a basic characteristic of the things the entity represents, an attribute may be "inherited" by the entity through a specific connection or categorization relationship in which it is a child or category entity. For example, if every employee is assigned to a department, then the attribute DEPARTMENT-NUMBER could be an attribute of EMPLOYEE which is inherited through the relationship of the entity EMPLOYEE to the entity DEPARTMENT. The entity DEPAR TMENT would be the owner of the attribute DEPARTMENT-NUMBER. Only primary key attributes may be inherited through a relationship. The attribute DEPARTMENT-NAME, for example, would not be an inherited attribute of EMPLOYEE if it was not part of the primary key for the entity DEPARTMENT.
Each attribute is identified by a unique name expressed as a noun phrase (a noun with optional adjectives and prepositions) that describes the characteristic represented by the attribute. The noun phrase is singular, not plural. Abbreviations and acronyms are permitted; however, the attribute name must be meaningful and consistent throughout the model. A formal definition of the attribute and a list of synonyms or aliases must be defined in the model glossary.
Attributes are shown by listing their names, one line per attribute, inside the associated entity box. Attributes which define the primary key are placed at the top of the list and separated from the other attributes by a horizontal line. See Figure 4-8.
Attributes which define the primary key are placed at the top of the attribute list within an entity box and separated from the other attributes by a horizontal line.
Each alternate key is assigned a unique integer number and is shown by placing the note "AK" plus the alternate key number in parentheses, e.g. "(AK1)", to the right of each of the attributes in the key. See Figure 4-9. An individual attribute may be identified as part of more than one alternate key. A primary key attribute may also serve as part of an alternate key.
 ATTRIBUTE NAME(AKn[,AKm])
ATTRIBUTE NAME(AKn[,AKm])
where n,m etc., uniquely identifies each Alternate Key that includes the associated attribute and where an Alternate Key consists of all the attributes with same identifier.
Figure 4-9 Alternate Key Syntax Example
An inherited attribute may be used as either a portion or total primary key, alternate key, or non-key attribute within an entity. For example, if tasks were only uniquely numbered within a project, then the inherited attribute PROJECT-ID would be combined with the owned attribute TASK-NUMBER to define the primary key of TASK. The entity PROJECT would have an identifying relationship with the entity TASK. If on the other hand, the attribute TASK-NUMBER is always unique, even between projects, then the inherited attribute PROJECT-ID would be a non-key attribute of the entity TASK. In this ease, the entity PROJECT would have a non-identifying relationship with the entity TASK. In a categorization relationship, both the generic entity and the category entities represent the same real-world thing. Therefore, the primary key for all category entities is inherited through the categorization relationship from the primary key of the generic entity. For example, if SALARIED-EMPLOYEE and HOURLY-EMPLOYEE are category entities and EMPLOYEE is the generic entity, then if the attribute EMPLOYEE-NUMBER is the primary key for the entity EMPLOYEE, it would also be the primary key for the enti ties SALARIED-EMPLOYEE and HOURLY-EMPLOYEE.
In some cases, a child entity may have multiple relationships to the same parent entity. The primary key of the parent entity would appear as inherited attributes in the child entity for each relationship. For a given instance of the child entity, the value of the inherited attributes may be different for each relationship, i.e. two different instances of the parent entity may be referenced. A bill of material structure, for example, can be represented by two entities PART and ASSEMBLE-STRUCTURE. The entity PART has a dual relationship as a parent entity to the entity ASSEMBLE-STRUCTURE. The same part sometimes acts as a component from which assemblies are made, i.e., a part may be a component in one or more assemblies, and sometimes acts as an assembly into which components are assembled, i.e., a part may be an assembly for one or more component parts. If the primary key for the entity PART is PART-NO, then PART-NO would appear twice in the entity ASSEMBLE-STRUCTURE as an inherited attribute.
When a single attribute is inherited more than once, a "role name" must be assigned to each occurrence. From the previous example, role names of COMPONENT-NO and ASSEMBLE-NO could be assigned to distinguish between the two inherited PART-NO attributes. Although not required, role names may also be used with single occurrences of inherited attributes to more precisely convey its meaning within the context of the child entity.
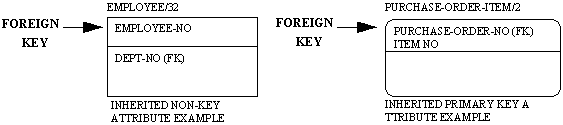
A foreign key is shown by placing the names of the inherited attributes inside the entity box and by following each with the letters "FK" in parentheses, i.e., "(FK)". See Figure 4-10. If the inherited attribute belongs to the primary key of the child entity, it is placed above the horizontal line and the entity is drawn with rounded corners to indicate that the identifier (primary key) of entity is dependent upon an attribute inherited through a relationship. If the inherited attribute does not belon g to the primary key of the child entity, it is drawn below the line. Inherited attributes may also be part of an alternate key.
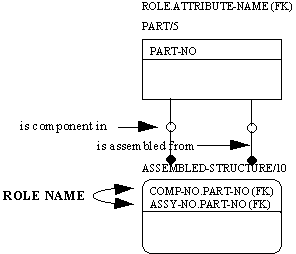 Role names, like attribute names, are noun phrases. A role name is followed by the name of the inherited attribute, separated by a period. See Figure 4-11.
Role names, like attribute names, are noun phrases. A role name is followed by the name of the inherited attribute, separated by a period. See Figure 4-11.
Figure 4-11 Role Name Syntax
The first phase of an IDEF1X modeling project is to state the purpose and scope of the model to be developed. An IDEF0 model may be developed to help define the scope of the model along with the identification of source materials and subject matter experts.
A candidate entity pool and definitions are developed as the first step in modeling. Additional entities will be added throughout the modeling process and the definitions will be refined.
The next step is identification of a preliminary set of relationships between the candidate entities. The model glossary is expanded to include relationships as well as entity definitions. The primary output of this phase is one or more entity-relationship level diagrams. An example is shown in Figure 4-12. At this stage of modeling, all entities are shown as square boxes, no attributes are shown, and non-specific (many-to-many) relationships are permitted.
The entity-relationship data model provides a stepping stone to the final, fully attributed data model. Since model building is a top-down approach, the entity-relationship model represents the broadest level to be considered in a data modeling project. It is useful at the planning level because it helps define initial business statements that represent constraints in the environment. It also aids in defining and validating data requirements.
The entity-relationship data model allows you to focus on some of the details at a time -- in this case, entities and their relationships -- rather than having to deal with a large amount of detail (characteristics of the objects and relationships) at once. The result is a reasonably digestible amount of information, which facilitates good data modeling.
The objectives of Phase 3 are to refine non-specific relationships, define key attributes for each entity, migrate primary keys to establish foreign keys, and validate relationships and keys. The primary result of this phase is one or more key-based model diagrams. An example is shown in Figure 4-13. The key-based model depicts primary, alternate, and foreign key attributes. Non-key attributes are not shown. A key-based model distinguishes between dependent and independent entities and between identify ing and non-identifying relationships. Role names and path assertions are also specified. Non-specific (many-to-many) relationships are not allowed at this level.
At the key-based level, the focus is on identifying the key attributes -- those characteristics and properties of the data that uniquely identify one entity instance from another. The key-based data model is a more precise representation of the data in the environment. The concept of key attributes is introduced as a more rigorous test for identifying real entities. Foreign keys are used to validate the identified relationships and to ensure that they make sense. A key-based data model may be used to begin the integration of a topical view with a broader view.
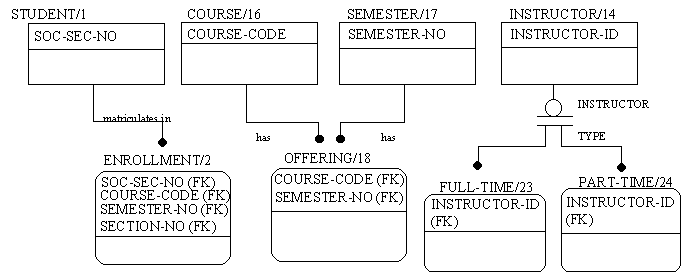
The final state of modeling is attribution. The objectives of this phase are to define non-key attributes, establish attribute ownership, and validate and refine the data structure. The result of Phase 4 is one or more fully attributed model diagrams, a completed glossary of entity, relationship, and attribute definitions and narrative statements of the modeled business rules. (See Figure 4-14)
Fully attributed data model views can be merged to provide a neutral, integrated data model of a specified subject area. This model then becomes the definition of conceptual schema. Since it contains all the attributes of the specified entities, it provides a complete and descriptive view of the data in the modeling subject area, thereby resolving any ambiguity that may have existed at the other levels. Although view integration can actually be done at each of the three data model levels, it is the ful ly attributed view that is the most useful in moving an organization to an integrated systems environment. Because the fully attributed data model is a stable, non-redundant, integrated view of data, databases designed from this perspective are flexible and have lengthy life cycles. This is because they are based on stable data structures rather than processes that frequently change.

4.2 IEW DATA MODEL
The IEW Data Model is based upon the information flows documented in the IEW Process Model. Inputs and Outputs of the IEW Process Model were decomposed into the Data Model contained here (Appendix D). The C2 Core Data Model formed the foundation of the IEW Data Model. It was selected because it accurately depicts the data elements necessary to accomplish C2 functions. Since all operations in IEW have some aspect of command and control, extending the C2 Core Data Model was a logical solution.
As a result of the decomposition of the IEW Process Model and the inheritance of the C2 Core Data Model, 378 entities and 1523 attributes were developed for the IEW Data Model. These figures include 207 entities and 623 attributes from the C2 Core Data Model.
 Previous Section
|
Next Section
Previous Section
|
Next Section